|
Email: yashgoyal.yg1-at-gmail.com I am a researcher interested in image generative modeling, Vision-Language Models (VLMs), bias analysis in Generative AI and Explainable AI. I am currently looking for job opportunities in related areas. Previously, I was a Research Scientist at Samsung AI Lab Montreal within Mila. I received my PhD in 2020 from the School of Interactive Computing at Georgia Tech. I was advised by Dhruv Batra. I also collaborated closely with Devi Parikh. I used to co-organize the annual VQA Challenge. As a research intern, I have spent time at Google Brain in spring+summer 2019, Facebook AI Research in spring+summer 2017, at Army Research Laboratory (ARL) Adelphi in summer 2015, and at Duke University in summer 2013. Email / CV / Google Scholar / arXiv |

|
|
|

|
|

|
|
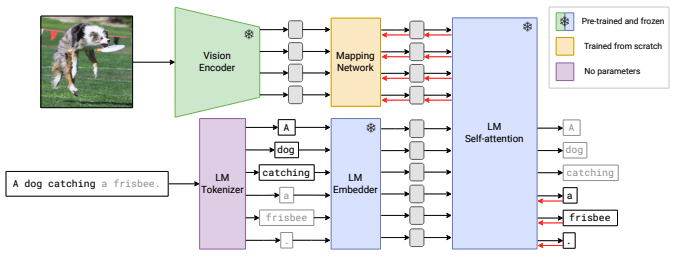
|
|

|
|

|
|
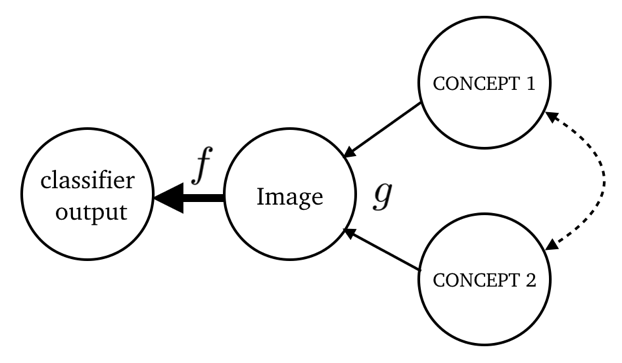
|
|
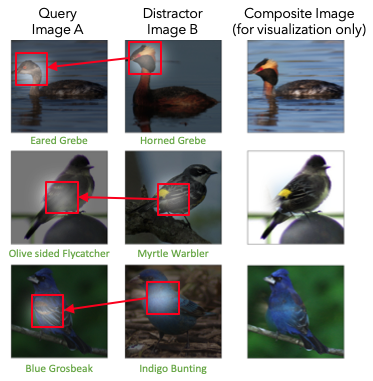
|
|

|
Project Website, Demo |
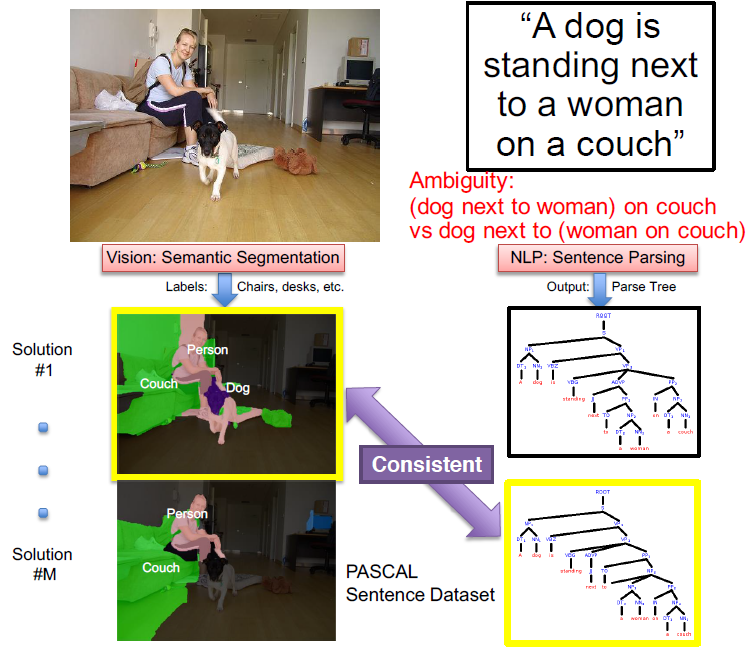
|
|
|
|
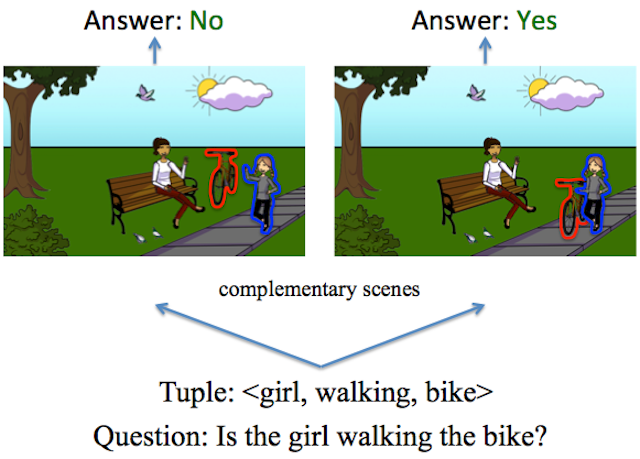
Project Website, Demo We counter the language priors present in the popular Visual Question Answering (VQA) dataset (Antol et al., ICCV 2015) and make vision (the V in VQA) matter! Specifically, we balance the VQA dataset by collecting complementary images such that every question in our balanced dataset is associated with not just a single image, but rather a pair of similar images that result in two different answers to the question. Our dataset is by construction more balanced than the original VQA dataset and has approximately twice the number of image-question pairs. Our complete balanced dataset will be publicly released as part of the 2nd iteration of the Visual Question Answering Challenge (VQA v2.0). |
|
|
We present an approach to simultaneously perform semantic segmentation and prepositional phrase attachment resolution for captioned images. We show that our vision and language modules have complementary strengths, and that joint reasoning produces more accurate results than any module operating in isolation. |

|
[Best Student Paper] Interactive Visualizations: Question and Image In this paper, we experimented with two visualization methods -- guided backpropagation and occlusion -- to interpret deep learning models for the task of Visual Question Answering. Specifically, we find what part of the input (pixels in images or words in questions) the VQA model focuses on while answering a question about an image. |
|
Data and Code We balance the existing VQA dataset so that VQA models are forced to understand the image to improve their performance. We propose an approach that focuses heavily on vision and answers the question by visual verification. Dataset and Code will be available soon! |
|
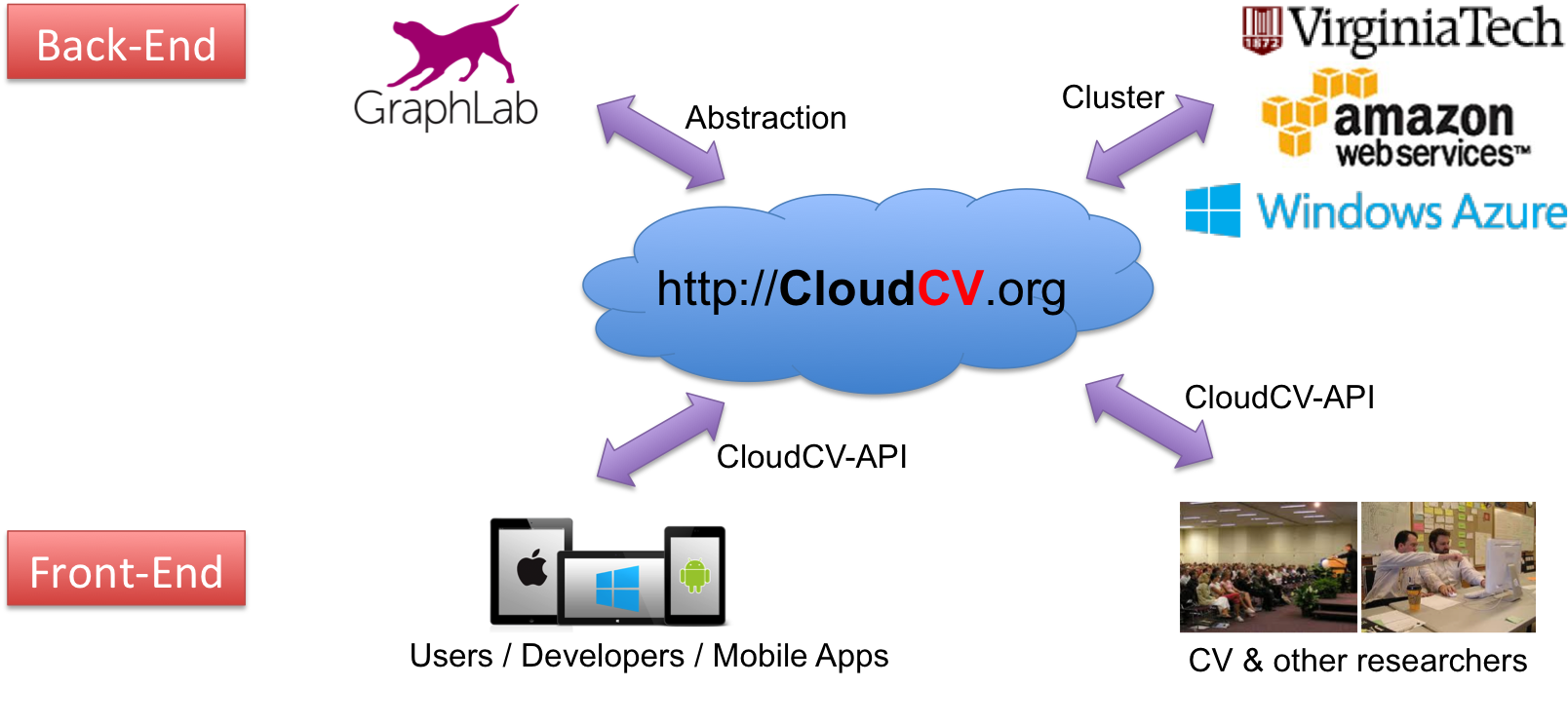
Editors: Gang Hua, Xian-Sheng Hua. Springer, 2015. Website We present a comprehensive system to provide access to state-of-the-art distributed computer vision algorithms as a cloud service through a Web Interface and APIs. |
|
|
|
|
-
"Counterfactual Visual Explanations" (1:04:00 - 1:08:25) [slides]
International Coference on Machine Learning (ICML), 2019.
-
"The Visual Question Answering Challenge" (1:06:29 - 1:11:40) [slides]
Special Session: Workshop Competitions, CVPR, 2018.
-
"Visual Question Answering Challenge 2018: Overview of Challenge, Winner Announcements, and Analysis of Results" [slides]
VQA Challenge and Visual Dialog Workshop, CVPR, 2018.
-
"Visual Question Answering Challenge 2017: Overview of Dataset, Challenge, Winner Announcements, and Analysis of Results" (38:38 - 47:12) [slides]
VQA Challenge Workshop, CVPR, 2017.
-
"Towards Transparent Visual Question Answering Systems" [slides]
Visualization for Deep Learning Workshop, ICML, 2016.
-
"Yin and Yang: Balancing and Answering Binary Visual Questions" [slides]
Mid-Atlantic Computer Vision (MACV) Workshop, 2016.